Profundización - HistoPyramid & PointBuilder
Se explicará la parte correspondiente a la implementación del algoritmo HistoPyramid de este ejemplo. Para observar el código comodamente se pueden dirigir a este repositorio. El ejemplo permite modificar la imagen resultante mediante la parametrización de un gran número de variables. Se recomienda que jueguen con el tablero de control antes de seguir leyendo para ver que es posible hacer con este ejemplo.
Para este ejemplo, lo que hace posible que el ray tracing funcione a una buena velocidad es el hecho que se utiliza HistoPyramid con marching cubes para sacar de una textura 2D que contiene realmente una imagen 3D, solo los puntos de interés para dibujar rápidamente el contorno de una superficie.
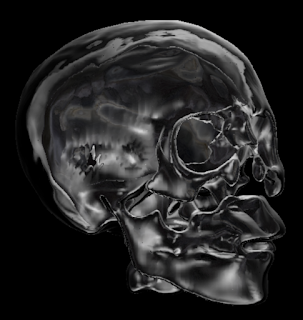
El contorno que se dibuja luce así con las opciones iniciales:

HistoPyramid es un algoritmo que permite hacer el feature extraction directamente desde la GPU. El nuevo proceso luce así:


Proceso del paso 3:
 Descripción: La matriz original, L0, que solo contiene datos binarios se divide en 4 celdas de tamaño 2x2. En cada una de estas celdas se suma el contenido que tiene por dentro. El resultado de la suma se almacena en una nueva matriz L1. El proceso se repite en L1, donde solo cabe una celda de tamaño 2x2, para generar la nueva matriz L2. El valor único que se obtiene en la matriz L2, nos indica el número total de pixeles con valores no-nulos. Estas tres matrices (L0, L1, L2), las guardamos, y nos sirve para obtener los indices de todos los puntos no nulos en la textura original. Nótese que este proceso sirve con matrices de cualquier tamaño (múltiplo de una potencia de 2). En casos con bases (L0) más grandes, se generan más niveles.
Descripción: La matriz original, L0, que solo contiene datos binarios se divide en 4 celdas de tamaño 2x2. En cada una de estas celdas se suma el contenido que tiene por dentro. El resultado de la suma se almacena en una nueva matriz L1. El proceso se repite en L1, donde solo cabe una celda de tamaño 2x2, para generar la nueva matriz L2. El valor único que se obtiene en la matriz L2, nos indica el número total de pixeles con valores no-nulos. Estas tres matrices (L0, L1, L2), las guardamos, y nos sirve para obtener los indices de todos los puntos no nulos en la textura original. Nótese que este proceso sirve con matrices de cualquier tamaño (múltiplo de una potencia de 2). En casos con bases (L0) más grandes, se generan más niveles.







Para este ejemplo, lo que hace posible que el ray tracing funcione a una buena velocidad es el hecho que se utiliza HistoPyramid con marching cubes para sacar de una textura 2D que contiene realmente una imagen 3D, solo los puntos de interés para dibujar rápidamente el contorno de una superficie.
El contorno que se dibuja luce así con las opciones iniciales:

Algoritmo HistoPyramid - PointBuilder
Antes de adentrarnos en cómo funciona HistoPyramid en el código de este ejemplo, vamos a decir en general de que trata este algoritmo.
Tradicionalmente, la GPU se ha utilizado para transformar rápidamente imágenes ya que estos procesos son altamente paralelizables. Sin embargo, para poder hacer feature point isolation tradicionalmente se recurre a hacer lo siguiente:

Esto tiene un problema grande y es que pasar información entre la CPU y la GPU es costoso.

Al tener todo en la GPU no se incide en el gran costo de estar pasando gran volúmenes de datos entre GPU y CPU constantemente.
El algoritmo consiste en 4 pasos, se presenta una ilustración gráfica seguidamente
- Transformar imagen 3D en imagen 2D haciendo slicing del volumen.
- Aplicar filtro a la imagen para transformar los datos de la imagen a datos binarios. Es decir, cada celda almacena un 0 o un 1 dependiendo si el filtro determina que la celda es activa (tiene información relevante) o no.
- A partir de esta transformación, vamos reduciendo la imagen aplicando sumas sobre cuadros 2x2 de la transformación inmediatamente anterior. Todos los cálculos intermedios son almacenados.
- Se utiliza las matrices obtenidas en el paso 3, llamado un HistoPyramid, para crear una tabla de búsqueda. Esta tabla de búsqueda solo nos dice las coordenadas de los pixeles/voxeles que están activos en la imagen original.
Ilustración de todo el proceso:

Proceso del paso 3:

Proceso del paso 4:


Descripción:
El primer paso es determinar cuantos indices se van a crear para crear nuestra lookup table. Esto es trivial, queremos poder tener un índice por pixel activo en la textura original. Es decir, queremos un número de indices igual a el número de celdas activas (el valor almacenado en la matriz superior de la pirámide que armamos en el punto anterior).
Para el key index actual, buscamos un pixel activo en coordenadas de la textura original. Para esto, el algoritmo va a recorrer la HistoPyramid de la siguiente forma:
Tenemos nuestro key index, y el current index que reside en el rango [start, end]. Comenzamos en la matriz superior de la pirámide, la que solo tiene un elemento.
Cada vez que el key index yace en el rango del current index en una celda particular en un nivel de la pirámide particular, descendemos en la pirámide.
- Start se inicializa en 0
- End se asigna como la suma del contenido de la celda actual de la histopyramid y start.
- Antes que se examine una nueva celda en el mismo nivel de la pirámide, start se vuelve el valor antiguo de end.
- Si descendemos un nivel, conservamos el valor actual de start.
Este proceso se repite hasta que llegamos al nivel base y no podemos descender más. Obtenemos las coordenadas en la textura original del pixel activo y se lo asignamos a nuestro key index.
Implementación en el Ejemplo
En el archivo view.js se encuentran las high-level functions que van decidiendo que programa (shaders) cargar para realizar el proceso de dibujado en el canvas. Es en este archivo donde inicialmente comienza el proceso de armar la HistoPyramid, para luego tener un Cloud Point.
La primera tarea que se realiza es inicializar las variables (texturas y framebuffers) donde se almacenaran todos los resultados que se calculan a la hora de construir la pirámide.

Notas sobre estas lineas:
- En tPyramid se va a almacenar todos los resultados de la pirámide uno al lado del otro en una sola textura.
- En tLevels se almacena cada nivel de la textura comenzando desde el top level de un solo elemento, hasta llegar al nivel N-1, 1024x1024.
- En fbPyramid se almacenan todos los frame buffers que escriben a las texturas.
- Hasta el momento todas estas texturas están vacías (no se le ha escrito nada en ellas).
Luego, se carga la imagen base, la textura original donde tenemos nuestro volumen en 3D representado en 2D por splices en la imagen.
Está imagen luce así:

Y el código para cargarla es el siguiente:

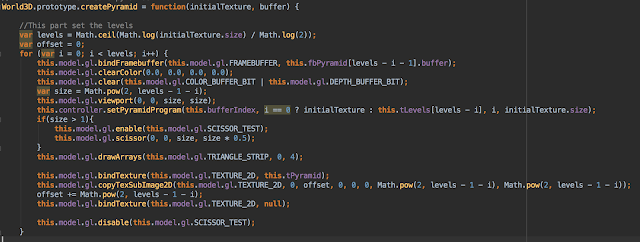
Para escribir los datos correspondientes a la realización del proceso de HistoPyramid en todas las texturas se hace un llamado a la siguiente función:

Cuya implementación luce así:

La primera linea determina el número de niveles que va a tener nuestra HistoPyramid (logaritmo en base de 2 del tamaño de la textura inicial que en este caso es 2048).
Luego, por cada nivel de la pirámide, primero hacemos un binding al frame buffer al que vamos a dibujar. Estos buffers los creamos hace 2 pasos entonces es solo determinar donde están ubicados. Al tener el frame buffer correspondiente binded, pasamos a limpiar sus contenidos.
Seguidamente, determinamos el tamaño del viewport que va a ser igual al tamaño de la textura a la que está escribiendo el buffer. También definimos cual es el programa de WebGL que vamos a utilizar para escribir en este frame buffer. En este caso es el "Pyramid Program" que mostraré muy pronto. Esta función inicializa todas las variables que le vamos a pasar a nuestros shaders. Nótese que dependiendo del nivel en el que estemos en la pirámide asignamos o la textura inicial, o la textura que se encuentra en el nivel anterior para realizar el paso de reducción.
Si no estamos en la última iteración en el for (if size > 1), entonces decimos que solo queremos dibujar en una sección de tamaño size x size/2. Finalmente dibujamos sobre el frame buffer utilizando triangle strips.
Al dibujar se invoca al siguiente vertex shader y fragment shader:
Vertex Shader:

Fragment Shader:

Se evidencia que es el fragment shader el que realiza el histograma de la pirámide al sumar las celdas activas que están entre la posición actual más K en tanto el eje X como en el eje Y.
Después de dibujar, solo queda almacenar el resultado en tPyramid, la variable que va juntando en una misma textura todas los niveles de la pirámide para poder crear luego el PointList (y por ende el cloud point).
Al salir del for-loop, se arma el PointList utilizando otro programa GLSL ParsePyramid.

Dado su extensión, no se incluye el fragment shader. Sin embargo, su función es clara, cada "key index" [0, # celdas activas] se va a asignar a la posición de un voxel activo.
Bitácora de Tiempo:
Se dispuso, y se consumieron, 12 horas para entender este fragmento del ejercicio. Entre extraer, y entender la estructura del proyecto, se consumieron 3 horas. Luego, para entender en que sección me iba enfocar se consumieron 2 horas. Leyendo y entendiendo la literatura sobre HistoPyramid se consumieron 5 horas. Finalmente, encontrar donde se estaba aplicando el algoritmo, y escribiendo el post se consumieron las 2 horas restantes.
https://pdfs.semanticscholar.org/74cc/9daf3f33b6c5132cbddc610e4db6ca1b17b5.pdf
https://folk.uio.no/erikd/histo/hpmarchertalk.pdf
http://docplayer.net/10483372-Gpu-point-list-generation-through-histogram-pyramids.html
Bibliografía:
https://pdfs.semanticscholar.org/74cc/9daf3f33b6c5132cbddc610e4db6ca1b17b5.pdf
https://folk.uio.no/erikd/histo/hpmarchertalk.pdf
http://docplayer.net/10483372-Gpu-point-list-generation-through-histogram-pyramids.html



Comentarios
Publicar un comentario